FP8量化#
W8A8-FP8 Dynamic量化#
activation和weight均采用per-tensor量化方式,weight离线做fp8量化,activation做动态在线量化。
运行示例如下:
python3 tools/run.py -c configs/qwen2_5/fp8_dynamic/qwen2_5-7b_instruct_fp8_dynamic.yaml
该配置文件中,量化相关参数如下:
name:压缩策略,选填量化quantization。quantization.name:压缩算法选填fp8_dynamic。quantization.bits:fp8量化对应填写8bit。quantization.quant_method:主要指定权重和激活的量化粒度为per-tensor。quantization.ignore_layers:需要忽略不进行量化的线性层。
compression:
name: PTQ
quantization:
name: fp8_dynamic
bits: 8
quant_method:
weight: "per-tensor"
activation: "per-tensor"
ignore_layers: # Skip quantization for these layers
- "lm_head"
W8A8-FP8 Static量化#
同样activation和weight均采用per-tensor量化方式,weight和activation均为离线做fp8量化。
运行示例如下:
python3 tools/run.py -c configs/qwen2_5/fp8_static/qwen2_5-7b_instruct_fp8_static.yaml
该配置文件中,压缩算法quantization.name选填fp8_static,其余量化配置与fp8动态量化相同。
激活静态量化需要指定校准数据集,例如使用sharegpt数据集:
dataset:
name: TextDataset
data_path: ./dataset/sharegpt_gpt4/sharegpt_gpt4_256.jsonl
max_seq_length: 4096
num_samples: 256
batch_size: 1
数据集相关参数如下:
name:校准数据集类型,文生文任务选择TextDataset。data_path:校准数据JSONL文件位置。max_seq_length:校准截断最大上下文长度。num_samples:校准最大样本个数。batch_size:校准批量大小。
支持数据格式详见数据准备文档。
产出模型#
在HuggingFace配置文件config.json中添加量化配置:
"quantization_config": {
"config_groups": {
"group_0": {
"targets": ["Linear"],
"input_activations": {
"num_bits": 8,
"strategy": "tensor",
"dynamic": false, //或者true
"type": "float"
},
"weights": {
"num_bits": 8,
"strategy": "tensor",
"dynamic": false,
"type": "float"
}
}
},
"format": "naive-quantized",
"ignore": [
"lm_head"
],
"quant_method": "compressed-tensors",
"quantization_status": "compressed"
},
可参阅vLLM FP8文档加载FP8量化模型配置要求。
FP8 low_memory量化#
标准FP8在量化较大模型时显存占用较高,可以采用low_memory模式FP8校准模型。
标准FP8静态量化Qwen3-235B-A22b、max_seq_len=4096开启low_memory优化节约显存情况如下表所示,单卡GPU即可实现量化。
Model |
优化前显存占用 |
开启low_memory模式 |
|---|---|---|
Qwen3-235B-A22b |
455GB |
22GB |
运行示例如下:
python3 tools/run.py -c configs/qwen3/fp8_static/qwen3-a22b_fp8_static_low_memroy.yaml
Low_memory激活静态量化需要指定开启,该配置文件中,压缩算法quantization填入low_memory: True,其余量化配置与fp8静态量化相同。
# Compression configuration
compression:
name: PTQ
quantization:
name: fp8_static
bits: 8
low_memory: True # Use less gpu/cpu memory
quant_method:
weight: "per-tensor"
activation: "per-tensor"
ignore_layers: # Skip quantization for these layers
- "lm_head"
开启FP8量化分析#
运行FP8动态、静态量化过程中可以通过开启quantization.quant_analyse来分析量化scale是否存在离群值。
示例:
python3 tools/run.py -c configs/qwen3/fp8_static/qwen3-0_6b_fp8_static_analyse.yaml
# Compression configuration
compression:
name: PTQ
quantization:
name: fp8_static
bits: 8
quant_method:
weight: "per-tensor"
activation: "per-tensor"
ignore_layers: # Skip quantization for these layers
- "lm_head"
quant_analyse: true
FP8量化文件后处理分析工具#
FP8量化分析工具可以分析您FP8的量化结果文件的scale分布情况以及对比bf16的权重分布情况,以便针对FP8难以拟合的权重分布进行单独处理。
运行示例如下:
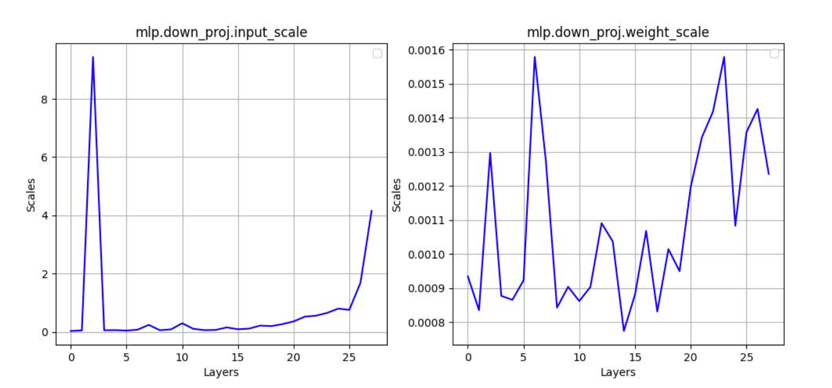
Scale分析#
运行脚本将会产出折线图与log分析。
python3 tools/fp8_quant_analyse.py --analyse-type act --model-path $FP8_PATH
相关参数如下:
model-path:[必填]FP8模型路径。save-path:[选填]结果保存路径。
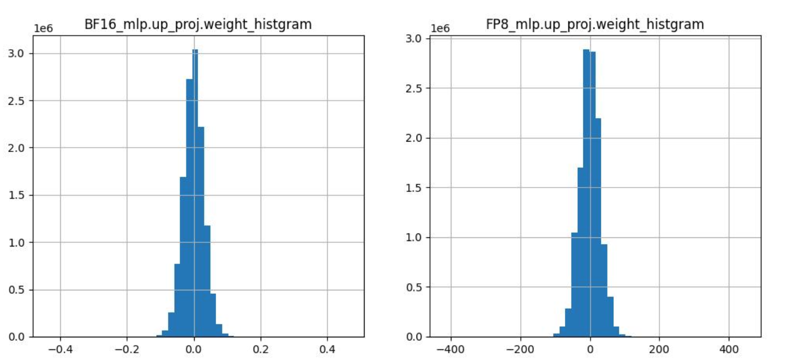
Weight分布对比#
运行脚本将会产出bf16精度与fp8精度权重直方图对比。
python3 tools/fp8_quant_analyse.py --analyse-type weight --bf16-path $BF16_PATH --fp8-path $FP8_PATH --layer-index 0
相关参数如下:
bf16-path:[必填]原精度模型路径。fp8-path:[必填]FP8模型路径。layer-index:[必填]需要分析的层index。save-path:[选填]结果保存路径。