Architecture概述#
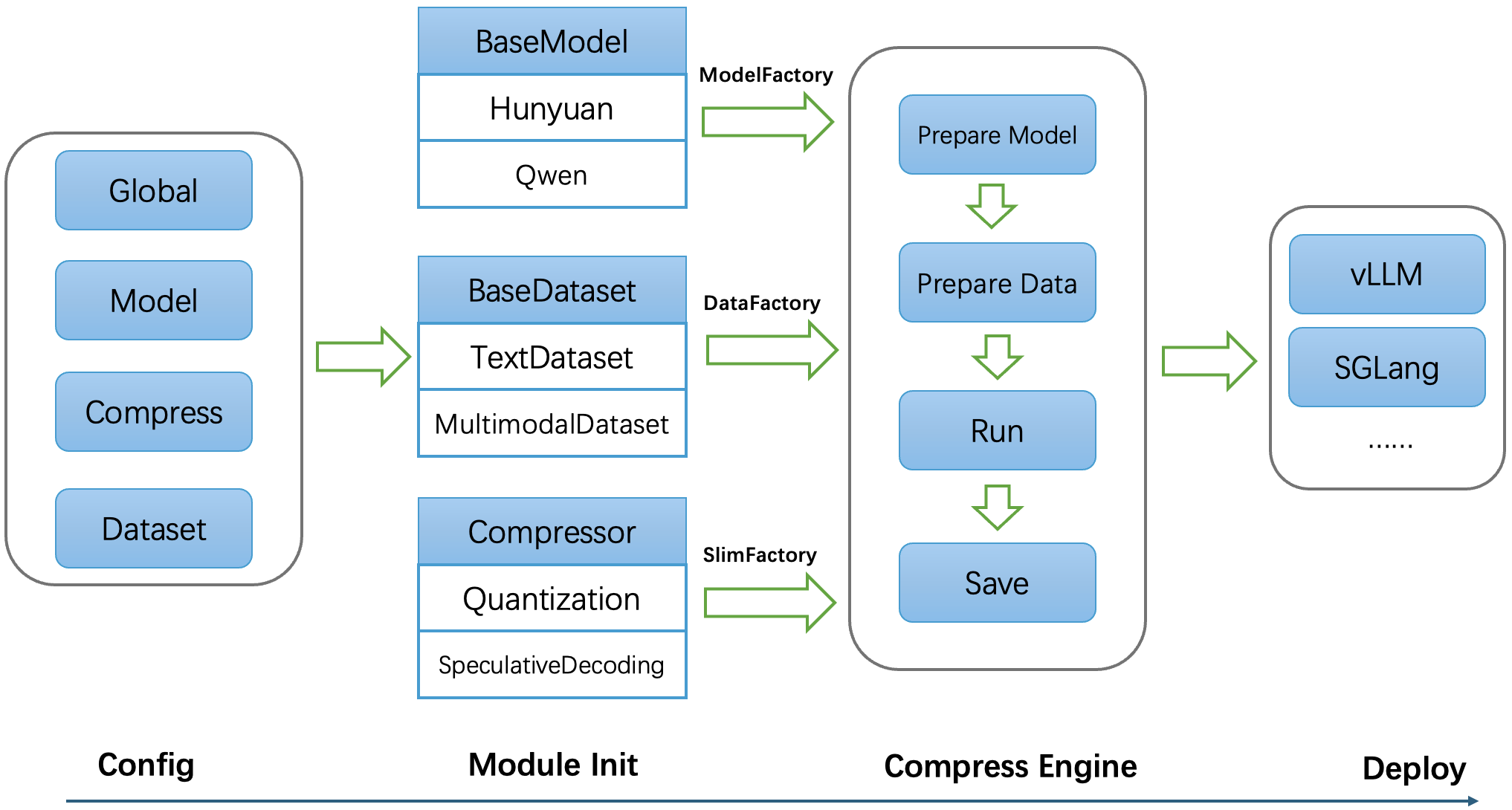
设计思路#
配置文件#
AngelSlim通过解析yaml配置文件来加载模型压缩要使用的相关配置项,包括模型信息、压缩算法信息和数据集相关信息。如下所示:
model:
name: Qwen
model_path: Qwen/Qwen3-1.7B
...
compression:
name: PTQ
quantization:
name: fp8_static
...
dataset:
name: TextDataset
...
具体配置文件详情请参考准备config文档
数据Dataloader#
AngelSlim中定义了一个DataLoaderFactory,用于封装各个数据集,创建dataloader:
dataloader = DataLoaderFactory.create_data_loader(
data_type=dataset_config.name,
processor=tokenizer,
device=model.device,
max_length=dataset_config.max_seq_length,
batch_size=dataset_config.batch_size,
shuffle=dataset_config.shuffle,
num_samples=dataset_config.num_samples,
data_source=data_path,
)
那么如何准备能让AngelSlim直接加载的数据呢,详情请参考准备数据文档
模型定义#
模型我们也采用注册的形式,利用ModelFactory进行模型的注册和调用:
class ModelFactory:
"""Factory for model creation using class decorator registration"""
# Registry to store mapping of class names to model classes
registry: Dict[str, Type] = {}
@classmethod
def register(cls, model_class: Type) -> Type:
"""Class decorator for automatic registration"""
class_name = model_class.__name__
if class_name in cls.registry:
raise ValueError(f"Model class '{class_name}' is already registered")
cls.registry[class_name] = model_class
return model_class
@classmethod
def create(
cls,
model_name: str,
quant_config: Optional[Any] = None,
model: Optional[Any] = None,
model_path: Optional[str] = None,
backend: str = "vllm",
**kwargs,
) -> Any:
"""Create an instance of the specified model"""
if model_name not in cls.registry:
available = ", ".join(cls.registry.keys())
raise ValueError(
f"Unknown model: '{model_name}'. Available models: {available}"
)
return cls.registry[model_name](
quant_config=quant_config,
model=model,
model_path=model_path,
backend=backend,
**kwargs,
)
模型可以这样定义:
@ModelFactory.register
class Qwen(BaseModel):
def __init__(
self,
quant_config=QuantConfig,
model=None,
model_path=None,
backend="vllm",
):
...
只需要在模型类前面加上@ModelFactory.register,就可以注册进入全局的模型列表中,程序可以很方便的调用全局模型列表中的各个模型。