Stem: Rethinking Causal Information Flow in Sparse Attention#
Stem 是 AngelSlim 的稀疏注意力算法,用于加速长上下文 LLM 的 Prefill 阶段。它通过在 block 粒度上估计注意力重要性,动态选择 top-k 关键块执行 block-sparse attention,在保持生成质量的同时大幅降低 Prefill 延迟。
1. 算法动机#
长上下文推理(如 32K–128K tokens)中,Prefill 阶段的全量 attention 计算是主要瓶颈:
计算量随序列长度 二次增长,显存和延迟双重压力
实际上大部分 attention block 对最终输出贡献极小,存在大量冗余
Stem 的核心思路是:先用低成本的 block-level scoring 估计每个 attention block 的重要性,再只对重要的 block 执行精确 attention。
2. 技术原理#
Stem 的 Prefill 过程分为三步:
2.1 Block-Level Scoring#
使用 Triton 加速的 strided group GEMM 计算下采样的 Q·K^T 分数矩阵,并结合 value-norm bonus 项,得到每个 query-block 对每个 key-block 的重要性估计:
$$\text{score}(Q_i, K_j) = \frac{Q_i \cdot K_j^T}{\sqrt{d} \cdot s \cdot n} + \lambda \cdot \text{ReLU}(\bar{v}_j)$$
其中 $s$ 为 stride 因子,$n$ 为归一化系数,$\bar{v}_j$ 为 value-norm 的标准化对数值。
2.2 Top-k Schedule#
每层根据预设的 keep-ratio 和 alpha 衰减因子,生成 per-block 的 top-k budget:
前 N 层(warmup):alpha=1.0,保留更多 block 以保证底层特征提取的完整性
后续层:alpha=0.7,更激进的稀疏化以加速计算
额外保证 initial blocks(sink tokens)和 sliding window blocks 始终被保留
2.3 Block-Sparse Attention#
根据 top-k mask 执行稀疏 attention:
如果安装了
block-sparse-attn库,使用真正的 block-sparse kernel否则自动 fallback 到 pseudo-sparse 实现(展开 mask 后做 dense attention)
HPC 后端支持 bf16 dense prefill 和 fp8 block-sparse prefill(varlen / paged 两种路径)
Decode 阶段不受影响,仍使用模型原始的 attention 实现(FlashAttention-2 / eager / SDPA)。
3. 支持范围#
维度 |
支持情况 |
|---|---|
后端 |
|
HPC 精度 |
bf16(dense prefill)、fp8(block-sparse prefill,varlen / paged) |
序列长度 |
无上限,建议 4K+ tokens 以体现加速效果 |
4. 性能评测#
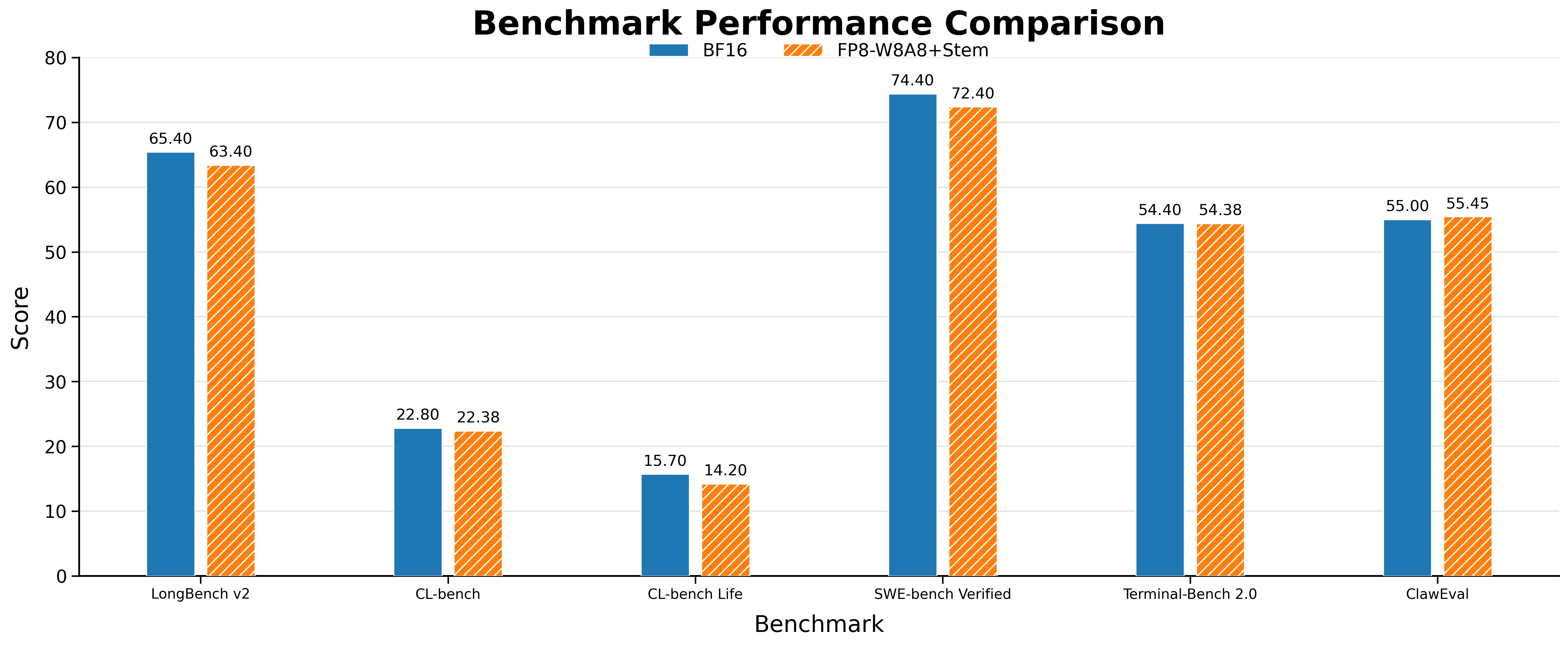
我们在长上下文与 Agent 类任务上评测了 Stem 的精度保持能力。在 FP8-W8A8 + Stem 配置下,模型在 LongBench v2、CL-bench、CL-bench Life、SWE-bench Verified、Terminal-Bench 2.0、ClawEval 等多个 benchmark 上的得分与 BF16 基线基本持平,部分任务(如 ClawEval)甚至略有提升,验证了 Stem 稀疏注意力在大幅加速 Prefill 的同时几乎无损模型质量。
5. 快速开始#
确保已安装 AngelSlim(pip install -e . 或 uv sync),然后在项目根目录运行:
Dense 对照(无 Stem patch)#
python tools/run_stem.py \
--mode dense \
--model-path /path/to/Qwen3-8B \
--prompt-file prompt.txt \
--max-new-tokens 160
Stem + HPC bf16#
python tools/run_stem.py \
--mode stem \
--stem-backend hpc \
--hpc-dtype bf16 \
--model-path /path/to/Qwen3-8B \
--prompt-file prompt.txt \
--max-new-tokens 160
Stem + HPC fp8#
python tools/run_stem.py \
--mode stem \
--stem-backend hpc \
--hpc-dtype fp8 \
--model-path /path/to/Qwen3-8B \
--prompt-file prompt.txt \
--max-new-tokens 160
使用自定义 prompt#
python tools/run_stem.py \
--mode stem \
--stem-backend hpc \
--hpc-dtype bf16 \
--model-path /path/to/Qwen3-8B \
--prompt-file my_long_document.txt \
--max-new-tokens 256
也可以通过封装脚本启动:
bash scripts/sparsity/run_stem.sh /path/to/Qwen3-8B prompt.txt stem
6. 参数说明#
参数 |
默认值 |
说明 |
|---|---|---|
|
|
后端选择: |
|
|
HPC 后端精度: |
|
|
FP8 执行路径: |
|
|
per-layer alpha 衰减因子,可传 list 实现分层控制 |
|
|
attention block 大小 |
|
|
scoring 阶段的下采样步长 |
|
|
scoring 阶段的分块宽度 |
|
|
scoring 阶段的额外归一化系数 |
|
|
始终保留的头部 block 数量(sink tokens) |
|
|
sliding window 保留的尾部 block 数量 |
7. 代码结构#
angelslim/compressor/sparsity/
├── __init__.py # re-export StemInference
└── stem/
├── __init__.py # 包入口
├── stem.py # StemInference 类(主入口)
├── patch.py # 模型 patch 逻辑
├── stem_configuration.py # StemConfig 配置
├── backends/
│ ├── dispatcher.py # torch / hpc 路由
│ ├── torch_impl.py # PyTorch + Triton 实现
│ └── hpc_impl.py # HPC C++ 扩展实现
├── modules/
│ └── forward.py # patched attention forward
└── ops/
└── stem_kernel.py # Triton kernel
tools/run_stem.py # 推理入口
scripts/sparsity/run_stem.sh # 启动脚本
8. Python API#
from angelslim.compressor.sparsity import StemInference
stem = StemInference(attn_kwargs={
"backend": "hpc",
"hpc_dtype": "fp8",
"stem_alpha": [1.0] * 5 + [0.7] * 31, # 36 层 Qwen3-8B
})
model = stem(model) # 返回 patched 后的同一个 model 对象